앞의 글
2024.01.07 - [Book] - 혼공학습단11기_혼공컴운 시작
혼공학습단11기_혼공컴운 시작
혼공학습단에 관심이 있던건 작년 10월이었나.. 개발 취준하시는 분들 블로그 몇 개를 정독하다가 다수의 분들이 활동을 하신 글을 올리시길래 뭐지?? 라는 생각에 찾아봤다. 그땐 모집기간도 아
suuuuung.tistory.com
2024.01.07 - [Book] - [혼공컴운]혼공학습단11기_1주차+기본, 선택미션
[혼공컴운]혼공학습단11기_1주차+기본, 선택미션
앞의 글 2024.01.07 - [Book] - 혼공학습단11기_혼공컴운 시작 혼공컴운 1주차 Chapter 1. 컴퓨터 구조 시작하기 01-1 컴퓨터 구조를 알아야 하는 이유. 시작하기 전에. 컴퓨터 구조는 개발자가 되려면 반드
suuuuung.tistory.com
2024.01.14 - [Book] - [혼공컴운]혼공학습단11기_2주차+기본, 선택미션
[혼공컴운]혼공학습단11기_2주차+기본, 선택미션
앞의 글 2024.01.07 - [Book] - 혼공학습단11기_혼공컴운 시작 2024.01.07 - [Book] - [혼공컴운]혼공학습단11기_1주차+기본, 선택미션 혼공컴운 2주차 Chapter 4. CPU의 작동원리 04-1 ALU와 제어장치. 시작하기 전
suuuuung.tistory.com
혼공컴운 3주차

Chapter 6. 메모리와 캐시 메모리
06-1 RAM의 특징과 종류.
시작하기 전에
앞서 1장에서 ‘주기억장치의 종류에는 크게 RAM과 ROM, 두 가지가 있고, ‘메모리’라는 용어는 그 중 RAM을 지칭하는 경우가 많다.’ 라고 언급했다.
이를 더 자세히 알기 위해 이번 챕터는 RAM, DRAM, SRAM, SDRAM, DDR SDRAM 에 대해 자세히 알아보자.
RAM의 특징
휘발성 저장 장치 [volatile memory] : 전원을 끄면 저장된 내용이 사라지는 저장 장치 (예. RAM)
비휘발성 저장 장치 [non-volatile memory] : 전원이 꺼져도 저장된 내용이 유지되는 저장 장치 (예. HDD, SSD, CD-ROM, USB 메모리와 같은 보조기억장치)
RAM의 용량과 성능
RAM의 용량이 충분히 크다면 보조기억장치에서 많은 데이터를 가져와 미리 RAM에 저장할 수 있다.
예를 들어 CPU를 책에 빗대보자.
보조기억장치를 책이 꽂혀 있는 책장, RAM은 책을 읽을 수 있는 책상으로 생각하게 되면 책상이 크다면 책장으로부터 많은 책을 미리 책상으로 가져와 여러 권을 동시에 읽을 수 있기 때문에 책을 가지러 왔다 갔다 하는 시간을 절약할 수 있다. >> RAM 용량이 크면 많은 프로그램들을 동시에 빠르게 실행하는 데 유리하다.
RAM의 종류
DRAM = Dynamic RAM
저장된 데이터가 동적으로 변하는(=사라지는) RAM을 의미.
시간이 지나면 저장된 데이터가 점차 사라지는 RAM, 고로 데이터 소멸을 막기 위해 일정 주기로 데이터를 재활성화(다시 저장) 해야 한다.
단점이 있지만 소비 전력이 비교적 낮고, 저렴하며, 집척도가 높기에 대용량으로 설계하기가 용이하다.
SRAM = Static RAM
저장된 데이터가 변하지 않는 RAM.
다만 DRAM과 달리 SRAM은 시간이 지나도 저장된 데이터가 사라지진 않음. 고로 데이터를 재활성화할 필요도 없다. 속도도 DRAM보다 빠름.
그렇지만 비휘발성 메모리가 아니다. 전원이 공급되지 않으면 저장된 내용이 없어지기에.
DRAM SRAM
| 재충전 | 필요함 | 필요 없음 |
| 속도 | 느림 | 빠름 |
| 가격 | 저렴함 | 비쌈 |
| 집적도 | 높음 | 낮음 |
| 소비 전력 | 적음 | 높음 |
| 사용 용도 | 주기억장치(RAM) | 캐시 메모리 |
SDRAM = Synchronous(동기화) Dynamic RAM
클럭 신호와 동기화된, 발전된 형태의 DRAM
즉, 클럭에 맞춰 동작하며 클럭마다 CPU와 정보를 주고 받을 수 있는 DRAM 이다.
DDR SDRAM = Double Data Rate SDRAM
최근 가장 흔히 사용되는 (대중적으로 쓰이는) RAM.
대역폭을 넓혀 속도를 빠르게 만든 SDRAM.
- 대역폭 : 데이터를 주고받는 길의 너비
SDR →(대역폭 2배씩 증가) DDR → DDR2 → DDR3 → DDR4
SDR SDRAM 보다 16배 넓은 대역폭을 가진 것인 DDR4 SDRAM 이다.
SDR SDRAM : 한 클럭 당 하나씩 데이터를 주고받을 수 있는 SDRAM.
마무리
핵심 포인트
- RAM은 휘발성 저장 장치이고 보조기억장치는 비휘발성 저장 장치
- DRAM은 시간이 지나면 저장된 데이터가 점차 사라지는 RAM이고, SRAM은 시간이 지나도 저장된 데이터가 사라지지 않는 RAM.
- SDRAM은 클럭과 동기화돤 DRAM
- DDR SDRAM은 SDR SDRAM에 비해 대역폭이 두 배 넓다.
06-2 메모리의 주소 공간.
시작하기 전에
앞에서 ‘메모리에 저장된 정보의 위치는 주소로 나타낼 수 있다.’ 정도로 설명했지만 사실 주소엔 두 종류가 있다. 물리 주소와 논리 주소.
물리 주소 : 메모리 하드웨어가 사용하는 주소
논리 주소 : CPU와 실행 중인 프로그램이 사용하는 주소.
물리 주소와 논리 주소
CPU와 실행 중인 프로그램은 현재 메모리 몇 번지에 무엇이 저장되어 있는지 다 알까? → X
메모리에 저장되 정보는 시시각각 변하기 때문이다.
메모리에는 새롭게 실행되는 프로그램이 시시때때로 적재되고, 실행이 끝난 프로그램은 삭제.
그리고 같은 프로그램을 실행하더라도 실행할 때마다 적재되는 주소가 달라질 수 있다.
물리 주소는 말 그대로 정보가 실제로 저장된 하드웨어상의 주소를 의미.
CPU와 실행 중인 프로그램이 사용하는 논리 주소는 실행 중인 프로그램 각각에게 부여된 0번지부터 시작되는 주소를 의미.
정리하자면, 물리 주소는 메모리 하드웨어 상의 주소이며 논리 주소는 CPU와 실행 중인 프로그램이 사용하는 주소이다.
그렇다면 논리 주소 → 물리 주소 변환은 어떻게 하는가?
메모리 관리 장치(MMU : Memory Management Unit) 라는 하드웨어에 의해 수행.
MMU는 CPU가 발생시킨 논리 주소에 베이스 레지스터 값(*)을 더하여 논리 주소를 물리 주소로 변환.
* 베이스 레지스터 값은 프로그램의 기존 주소 라고 생각하면 된다. (챕터 4-1 中 레지스터 파트에 나옴.)
예시로 현재 베이스 레지스터에 15000이 저장, CPU가 발생시킨 논리 주소가 100번지라면 이 논리 주소는 아래 그림처럼 물리 주소 15100번지(100 + 15000)로 변환된다.
** 그림 추가.
다른 예시로 베이스 레지스터에 45000이 저장, CPU가 발생시킨 논리 주소가 100번지라면 이 논리 주소는 물리 주소 45100(100 + 45000) 번지로 변환된다.
베이스 레지스터는 프로그램의 가장 작은 물리 주소, 즉 프로그램의 첫 물리 주소는 저장하는 셈이며 논리 주소는 프로그램의 시작점으로부터 떨어진 거리이다.
메모리 보호 기법
프로그램의 논리 주소 영역을 벗어났다면 오류가 있는 명령어들은 실행되어서는 안된다.
이렇게 다른 프로그램의 영역을 침범할 수 있는 명령어는 위험하기에 논리 주소 범위를 벗어나는 명령어 실행을 방지하고 실행 중인 프로그램이 다른 프로그램에 영향을 받지 않도록 보호할 방법이 필요하다. → 한계 레지스터 (limit register) 가 담당.
부연 설명하자면 베이스 레지스터가 실행 중인 프로그램의 가장 작은 물리 주소를 저장한다면, 한계 레지스터는 논리 주소의 최대 크기를 저장한다. = 프로그램의 물리 주소 범위는 베이스 레지스터 값 이상, 베이스 레지스터 값 + 한계 레지스터 값 미만이 된다.
정리하자면 한계 레지스터는 논리 주소의 최대 크기를 저장한다.
추가로, CPU는 메모리에 접근하기 전에 접근하고자 하는 논리 주소가 한계 레지스터보다 작은지를 항상 검사한다. 만약 CPU가 한계 레지스터보다 높은 논리 주소에 접근하려고 하면 인터럽트(트랩)를 발생시켜 실행을 중단한다.
이러한 방식으로 실행 중인 프로그램의 독립적인 실행 공간을 확보하고 하나의 프로그램이 다른 프로그램을 침범하지 못하게 보호할 수 있다. = 접근하고자 하는 논리 주소가 한계 레지스터보다 작은지를 검사함으로써 메모리 내의 프로그램을 보호할 수 있다.
마무리
핵심 포인트
- 물리 주소는 메모리 하드웨어상의 주소이고, 논리 주소는 CPU와 실행 중인 프로그램이 사용하는 주소이다.
- MMU는 논리 주소를 물리 주소로 변환한다.
- 베이스 레지스터는 프로그램의 첫 물리 주소를 저장한다.
- 한계 레지스터는 실행 중인 프로그램의 논리 주소의 최대 크기를 저장한다.
06-3 캐시 메모리.
시작하기 전에
저장 장치 계층 구조를 통해 저장 장치의 큰 그림을 그리고, CPU와 메모리 사이에 위치한 캐시 메모리를 학습.
저장 장치 계층 구조.
저장 장치의 2가지의 명제를 따른다.
- CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다.
- 속도가 빠른 저장 장치는 저장 용량이 작고, 가격이 비싸다.
그래서 일반적으로 컴퓨터는 장단점이 명확한 저장 장치들로 인해 다양한 저장 장치를 모두 사용할 수 밖에 없다.
이 때, 사용하는 저장 장치들은 'CPU에 얼마나 가까운가' 를 기준으로 계층적으로 나타낼 수 있는데 이를 저장 장치 계층 구조라 부른다.
저장 장치 계층 구조 : 각기 다른 용량과 성능의 저장 장치들을 계층화 하여 표현한 구조.
캐시 메모리.
캐시 메모리 : CPU와 메모리 사이에 위치하고, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치.
CPU의 연산 속도와 메모리 접근 속도의 차이를 조금이나마 줄이기 위해 탄생.
컴퓨터 내부에는 여러 개의 캐시 메모리가 있는데, 이 캐시 메모리 들은 CPU(코어) 와 가까운 순서대로 계층을 구성한다. 코어와 가장 가까운 캐시 메모리를 L1(Level 1) 캐시, 그 다음 가까운 캐시 메모리를 L2 캐시, 그 다음 가까운 캐시 메모리를 L3 캐시 라고 부른다. 일반적으로 L1, L2 캐시는 내부, L3 는 외부에 위치한다.
저장 장치 계층 구조를 이해했다면 알 수 있는 부분들.
캐시 메모리의 용량은 L1, L2, L3 순으로 커지고, 속도는 L3, L2, L1 순으로 빨라진다. 가격은 일반적으로 L3 -> L1 순으로 비싸진다. CPU가 메모리 내에 데이터가 필요하다 판단하면 L1 캐시에 해당 데이터가 있는지를 알아보고 없다면 L2, L3 순으로 데이터를 검색한다.
분리형 캐시
코어와 가장 가까운 L1 캐시는 조금이라도 접근 속도를 빠르게 만들기 위해 명령어만을 저장하는 L1 캐시인 L1I 캐시와 데이터만을 저장하는 L1 캐시인 L1D 캐시로 분리하는 경우도 있다. 이를 분리형 캐시라 한다.
참조 지역성 원리.
보조 기억 장치는 전원이 꺼져도 기억할 대상을 지정, 메모리는 실행 중인 대상을 저장한다면 캐시 메모리는 CPU가 사용할 법한 대상을 예측하여 저장. 이때 자주 사용될 것으로 예측한 데이터가 실제로 들어맞아 캐시 메모리 내 데이터가 CPU에서 활용될 경우를 캐시 히트 [cache hit] 라고 한다.
반대의 경우는 캐시 미스[cache miss]라고 한다.
캐시 미스가 발생하면 CPU가 필요한 데이터를 메모리에서 직접 가져와야 하기 때문에 캐시 메모리의 이점을 활용 X.
자주 발생한다면 성능이 떨어진다.
캐시 적중률 : 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
캐시 적중률이 높으면 CPU의 메모리 접근 횟수를 줄일 수 있다.
캐시 메모리는 한 가지 원칙에 따라 메모리부터 가져올 데이터를 결정하는데 이를 참조 지역성의 원리라 한다.
참조 지역성의 원리 : CPU가 메모리에 접근할 때의 주된 경향을 바탕으로 만들어진 원리
아래와 같은 경향을 바탕으로 만들어졌다.
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다.
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다.
1번 경향에서 언급한 '최근에 접근했던 메모리 공간에 다시 접근하려는 경향' 을 시간 지역성 [temporal locality] 라 한다.
2번 경향에서 언급한 '접근한 메모리 공간 근처를 접근하려는 경향' 을 공간 지역성 [spatial locality] 라고 한다.
이렇듯 캐시 메모리는 참조 지역성의 원리에 입각하여 CPU가 사용할 법한 데이터를 예측한다.
마무리
핵심 포인트
- 저장 장치 계층 구조는 각기 다른 용량과 성능의 저장 장치들을 계층화화여 표현한 구조.
- 캐시 메모리는 CPU의 연산 속도와 메모리 접근 속도의 차이를 줄이기 위한 저장 장치.
- 캐시 적중률이 높으면 CPU의 메모리 접근 횟수를 줄일 수 있다.
- 캐시 메모리는 참조 지역성의 원리에 따라 데이터를 예측하여 캐시 적중률을 높힌다.
Chapter 7. 보조기억장치
07-1 다양한 보조기억장치
시작하기 전에
HDD, 플래시 메모리에 대해 알아보자.
하드 디스크
하드 디스크 : 자기적인 방식으로 데이터를 저장하는 보조기억장치.
그래서 자기 디스크의 일종이라고 지칭하기도 함.
하드 디스크 내 동그란 원판을 플래터 [platter], 그 플래터를 회전시키는 구성 요소를 스핀들 [spindle]
스핀들이 플래터를 돌리는 속도는 RPM 단위를 사용.
플래터를 대상으로 데이터를 읽고 쓰는 구성 요소는 헤드 [head]
헤드엔 디스크 암 [disk arm]이 부착되어 있는데 이는 원하는 위치로 헤드를 이동시킬 때 사용.
플래터는 트랙 [track] 과 섹터 [sector] 라는 단위로 데이터를 저장한다.
하나의 섹터를 묶어 블록 [block](*) 이라고 표현하기도 한다.
(*) : 운영체제 파트 中 파일 시스템에서 더 구체적으로 배울 예정이다.
여러 겹의 플래터 상에서 같은 트랙이 위치한 곳을 모아 연결한 논리적 단위를 실린더 [cylinder] 라 한다.
하드 디스크가 저장된 데이터에 접근하는 시간은 크게 탐색시간, 회전지연, 전송시간으로 나뉜다.
탐색 시간 [seek time] : 접근하려는 데이터가 저장된 트랙까지 헤드를 이동시키는 시간.
회전 지연 [rotational latency] : 헤드가 있는 곳으로 플래터를 회전시키는 시간.
전송 시간 [transfer time] : 하드 디스크와 컴퓨터 간에 데이터를 전송하는 시간.
플래시 메모리
플래시 메모리 [flash memory] :전기적으로 데이터를 읽고 쓸 수 있는 반도체 기반의 저장 장치.
두 종류의 플래시 메모리가 있다. NAND 과 NOR
이 책에서는 NAND 플래시 메모리를 지칭하며, NOR 플래시 메모리는 특별한 언급을 할 예정이다.
셀 [cell] : 플래시 메모리에서 데이터를 저장하는 가장 작은 단위
단위는 셀을 사용하며 한 셀에 1비트를 저장할 수 있는 플래시 메모리를 SLC타입, 2비트를 저장할 수 있는 플래시 메모리를 MLC타입, 3비트의 경우는 TLC타입 이라한다.
| 구분 | SLC | MLC | TLC |
| 셀당 bit | 1 bit | 2 bit | 3 bit |
| 수명 | 길다 | 보통 | 짧다 |
| 읽기/쓰기 속도 | 빠름 | 보통 | 느림 |
| 용량 대비 가격 | 높음 | 보통 | 낮음 |
페이지 [page] : 셀들이 모여 만들어진 단위.
블록 [block] : 페이지가 모여 만들어진 단위.
플레인 [plane] : 블록이 모여 만들어진 단위.
다이 [die] : 플레인이 모여 만들어진 단위.
페이지가 가질 수 있는 세 개의 상태.
Free 상태 : 어떠한 데이터도 저장하고 있지 않아 새로운 데이터를 저장할 수 있는 상태
Valid 상태 : 이미 유효한 데이터를 저장하고 있는 상태
Invalid 상태 : 쓰레기값이라 부르는 유효하지 않은 데이터를 저장하고 있는 상태.
플래시 메모리는 하드 디스크와 달리 덮어쓰기가 불가능하므로 Valid 상태에선 새 데이터 저장X.
최근의 플래시 메모리에는 가비지 컬렉션이란 기능을 제공한다.
가비지 컬렉션 : 유효한 페이지들만을 새로운 블록으로 복사한 뒤, 기존의 블록을 삭제하는 기능
마무리
핵심 포인트
- 하드 디스크의 구성 요소에는 플래터, 스핀들, 헤드, 디스크 암이 있다.
- 플래터는 트랙과 섹터로 나뉘고, 여러 플래터의 동일한 트랙이 모여 실린더를 이룬다.
- 하드 디스크의 데이터 접근 시간은 크게 탐색 시간, 회전 지연, 전송 시간으로 나뉜다.
- 플래시 메모리는 한 셀에 몇 비트를 저장할 수 있느냐에 따라 SLC, MLC, TLC 로 나뉜다.
- 플래시 메모리의 읽기와 쓰기는 페이지 단위로, 삭제는 블록 단위로 이루어진다.
07-2 RAID의 정의와 종류
시작하기 전에
RAID가 무엇이고, 레벨에 따른 차이를 알아보자.
RAID의 정의
하드 디스크와 SSD를 사용하는 기술로, 데이터의 안전성 혹은 높은 성능을 위해 여러 개의 물리적 보조기억장치를 마치 하나의 논리적 보조기억장치처럼 사용하는 기술을 의미.
RAID의 종류
RAID 구성 방법을 RAID 레벨 이라 표현하는데 0 ~ 6이 있고, 그로부터 파생된 10, 50 등이 있다.
RAID [Redundant Array of Independent Disks]
RAID 0, RAID 10 이렇게 표현.
RAID 0
여러 개의 보조기억장치에 데이터를 단순히 나누어 저장하는 구성 방식.
단점 : 저장된 정보가 안전하지 않다.
RAID 1 (RAID 0의 단점을 보완하기 위해)
복사본을 만드는 방식이며 미러링 이라고도 부른다.
장점 : 복구가 매우 간단함.
단점 : 복사본을 위해 많은 양의 하드 디스크가 필요하게 되어 비용이 증가한다.
RAID 4
RAID 1 처럼 완전한 복사본을 만드는 대신 오류를 검출하고 복구하기 위한 정보를 저장한 장치를 두는 구성 방식이다.
위의 설명에서 ‘오류를 ~정보’ 부분을 패리티 비트 라고도 한다.
패리트 비트는 오류 검출만 가능하고 오류 복구가 불가능하지만, RAID 에 한해서는 패리티 값으로 오류 수정도 가능하다.
RAID 5 (RAID 4의 단점 보완)
RAID 4의 문제인 병목 현상을 해소하기 위해 패리티를 분산하여 저장하는 방식이다.
RAID 6
기본적으로 RAID 5와 같으나, 서로 다른 두 개의 패리티를 두는 방식이다. 즉 오류를 검출 및 복구할 수단이 2개가 생긴 셈이다. 그래서 앞서 소개한 RAID 종류들 보다 더 안전한 구성이다.
장점 : RAID 4, RAID 5 보다 안전한 구성.
단점 : 쓰기 속도가 RAID 5보다 느리다.
각 RAID 에 따라 장단점은 존재하므로 각 사용하는 상황에 따라 무엇을 최우선으로 원하는지에 따라 최적의 RAID 레벨은 달라질 수 있다는 점을 알아야 한다.
마무리
- RAID란 데이터의 안전성 혹은 높은 성능을 위해 여러 하드 디스크나 SSD를 마치 하나의 장치처럼 사용하는 기술이다.
- RAID 0는 데이터를 단순히 병렬로 분산하여 저장하고, RAID 1은 완전한 복사본을 만든다.
- RAID 4는 패리티를 저장한 장치를 따로 두는 방식이고, RAID 5는 패리티를 분산하여 저장하는 방식
- RAID 6는 서로 다른 두 개의 패리티를 두는 방식
Chapter 8. 입출력장치
08-1 장치 컨트롤러와 장치 드라이버
시작하기 전에
장치 컨트롤러와 장치 드라이버라는 개념을 통해 다양한 외부 장치가 컴퓨터 내부와 어떻게 연결, 소통이 되는지 알아보자.
** 이번 장에서 언급하는 입출력장치는 앞서 7장에서 학습한 보조기억장치도 포함한다.
장치 컨트롤러
먼저 입출력장치는 왜 CPU, 메모리보다 다루기 더 까다로운가?
- 입출력장치의 종류는 너무 많다.
- 일반적으로 CPU와 메모리의 데이터 전송률은 높지만 입출력장치의 데이터 전송률은 낮다.
전송률 : 데이터를 얼마나 빨리 교환할 수 있는지를 나타내는 지표.
위와 같은 이유 (특히 2번)로 장치 컨트롤러 [device controller] 라는 하드웨어를 통해 연결한다.
장치 컨트롤러는 입출력 제어기. 입출력 모듈 등으로 불리기도 한다.
아래 3가지의 문제를 해결한다.
- CPU와 입출력장치 간의 통신 중개
- 오류 검출
- 데이터 버퍼링
버퍼링 : 전송률이 높은 장치와 낮은 장치 사이에 주고받는 데이터를 버퍼라는 임시 저장 공간에 저장하여 전송률을 비슷하게 맞추는 방법.
장치 컨트롤러의 내부 구조는 복잡하지만 3가지는 기억하자.
- 데이터 레지스터 : CPU와 입출력장치 사이에 주고받을 데이터가 담기는 레지스터. 단, 최근 주고받는 데이터가 많은 입출력장치에선 레지스터 대신 RAM을 사용하기도 함.
- 상태 레지스터 : 입출력장치가 입출력 작업을 할 준비가 되었는지, 입출력 작업이 완료되었는지, 입출력장치에 오류가 없는지 등의 상태 정보를 저장.
- 제어 레지스터 : 입출력장치가 수행할 내용에 대한 제어 정보와 명령을 저장.
장치 드라이버
장치 컨트롤러의 동작을 감지하고 제어함으로써 장치 컨트롤러가 컴퓨터 내부와 정보를 주고받을 수 있게 하는 프로그램.
장치 컨트롤러가 입출력장치를 연결하기 위한 하드웨어적 통로라면, 장치 드라이버는 소프트웨어적인 통로이다.
마무리
핵심 포인트
- 입출력장치는 장치 컨트롤러를 통해 컴퓨터 내부와 정보를 주고받는다.
- 장치 드라이버는 장치 컨트롤러가 컴퓨터 내부와 정보를 주고받을 수 있게 하는 프로그램이다.
08-2 다양한 입출력 방법
시작하기 전에
프로그램 입출력, 인터럽트 기반 입출력, DMA 입출력을 알아보자.
프로그램 입출력
기본적으로 프로그램 속 명령어로 입출력장치를 제어하는 방법.
CPU가 프로그램 속 명령어를 실행하는 과정에서 입출력 명령어를 만나면 CPU는 입출력장치에 연결된 장치 컨트롤러와 상호작용하며 입출력 작업을 수행.
수행 방법은 메모리 맵 입출력, 고립형 입출력이 있다.
메모리 맵 입출력은 메모리에 접근하기 위한 주소 공간과 입출력장치에 접근하기 위한 주소 공간을 하나의 주소 공간으로 간주하는 방법
고립형 입출력은 메모리를 위한 주소 공간가 입출력장치를 위한 주소 공간을 분리하는 방법
고립형 입출력 방식에서 CPU는 입출력장치에 접근하기 위해 메모리에 접근하는 명령어와는 다른 (입출력 읽기/쓰기 선을 활성화시키는) 입출력 전용 명령어를 사용함.
| 메모리 맵 입출력 | 고립형 입출력 |
| 메모리와 입출력장치는 같은 주소 공간 사용 | 메모리와 입출력장치는 분리된 주소 공간 사용 |
| 메모리 주소 공간이 축소됨. | 메모리 주소 공간이 축소되지 않음 |
| 메모리와 입출력장치에 같은 명령어 사용 가능 | 입출력 전용 명령어 사용 |
인터럽트 기반 입출력
인터럽트를 기반으로 하는 입출력.
** 복습해야할 것들 (인터럽트 기반 입출력 파트 학습할 때 복습하고 들어가는 것이 좋다는 강사님 말씀.)
- 하드웨어 인터럽트의 개념
- 플래그 인터럽트 속 인터럽트 비트
- 인터럽트 요청 신호
- 인터럽트 서비스 루틴
플래그 레지스터 속 인터럽트 비트가 활성화되어 있는 경우, 혹은 인터럽트 비트를 비활성화해도 무시할 수 없는 인터럽트인 NMI [Non-Maskable Interrupt] 가 발생한 경우 CPU는 이렇게 우선순위가 높은 인터럽트부터 처리한다.
우선순위를 반영해 다중 인터럽트를 처리하는 방법 중 대중적인 방법은 프로그래머블 인터럽트 컨트롤러(이하 PIC) 라는 하드웨어를 사용하는 방법이다.
PIC 란 여러 장치 컨트롤러에 연결되어 장치 컨트롤러에서 보낸 하드웨어 인터럽트 요청들의 우선순위를 판별 후 CPU에 즉시 처리해야할 하드웨어 인터럽트는 무엇인지 알려주는 장치이다.
DMA 입출력
입출력장치와 메모리가 CPU를 거치지 않고도 상호작용할 수 있는 입출력 방식
이를 수행하기 위해선 시스템 버스에 연결된 DMA 컨트롤러라는 하드웨어가 필요하다.
입출력 버스
입출력장치를 컴퓨터 내부와 연결 짓는 통로.
종류로는 PCI 버스, PCI Express(PCle) 버스가 있다.
마무리
핵심 포인트
- 프로그램 입출력은 프로그램 속 명령어로 입출력 작업을 하는 방식이다.
- 메모리 맵 입출력은 메모리에 접근하기 위한 주소 공간과 입출력장치에 접근하기 위한 주소 공간을 하나의 주소 공간으로 간주하는 입출력 방식이다.
- 고립형 입출력은 메모리에 접근하기 위한 주소 공간가 입출력장치에 접근하기 위한 주소 공간을 별도로 분리하는 입출력 방식
- 인터럽트 기반 입출력은 인터럽트로써 입출력을 수행하는 방법
- DMA 입출력은 CPU를 거치지 않고 메모리와 입출력장치 간의 데이터를 주고받는 입출력 방식.
- 입출력 버스는 입출력장치와 컴퓨터 내부를 연결 짓는 통로로, 입출력 작업 과정에서 시스템 버스 사용 횟수를 줄여준다.
기본 미션
p.185의 확인 문제 3번, p.205의 확인 문제 1번 풀고 인증하기

p.185 확인 문제 3번 인증.
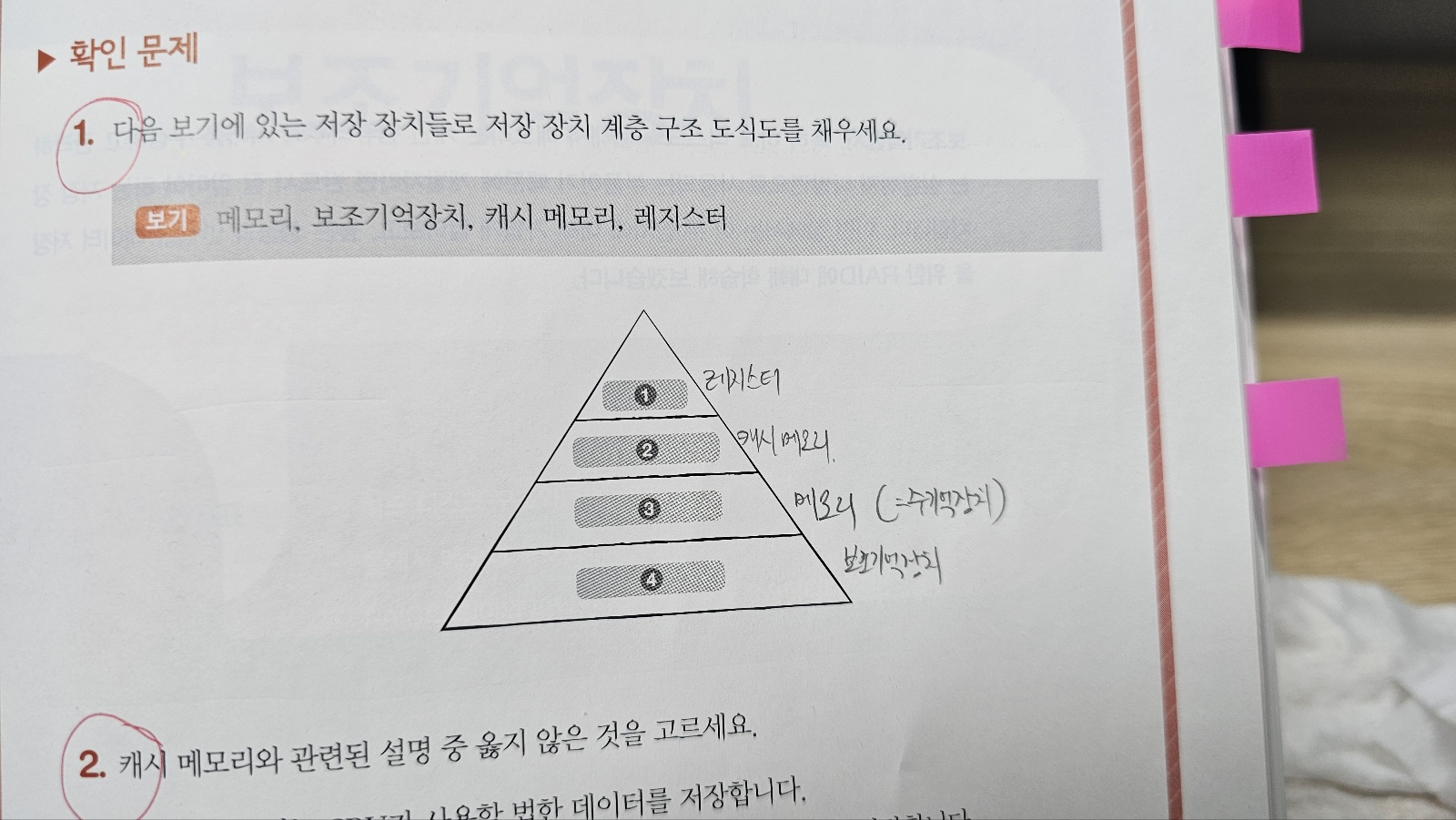
p.205 확인 문제 1번 인증.
선택 미션
Ch.07(07-1) RAID의 정의와 종류를 간단히 정리해보기.
RAID : [ Redundant Array of Independent Disks ] 의 약어, 여러 개의 하드 디스크 드라이브를 하나의 논리적인 단위로 묶어 데이터의 성능 향상과 안정성 향상을 위한 기술이다.
종류로는 RAID 0(Striping), RAID 1(Mirroring), RAID 5(Striping with Parity), RAID 6(Striping with Dual Parity), RAID 10 (Combination of RAID 1 and RAID 0), RAID 50 (Combination of RAID 5 and RAID 0), RAID 60 (Combination of RAID 6 and RAID 0) 등이 있다.
3주차 마무리 소감
이번 3주차 과정은 컴퓨터 구조의 마지막 파트여서 그런지 앞에 나온 내용들이 저번 2주차보단 많이 나온 느낌이다. 그래서 그런지 인강에서도 강사님이 "어느 파트에 나온 내용입니다.", "앞에서 배운 ~~~" 이라는 말을 체감상 거의 매 파트마다 이야기하신 것 같다.
이번에도.. 3회독을 강제적으로 했다. ㅋㅋ;; 2주에 걸쳐서 3회독을 하다보니 매번 새로 배우는 느낌으로 책을 보고 있다. 그렇다고 까먹어서 새로 배웠다는 의미는 아니고, 볼 때마다 조금이라도 알고 다시 책에 적힌 문장을 보는 것이니 그만큼 이해가 잘된다. 회독 방식은 똑같았지만 책 내용 정리하면서 책의 그림을 다른 분들처럼 넣어보고 싶다는 생각이 많이 들었던 3주차이다. 내가 이 정리본들을 혼공학습단이 끝난 후 본다면... 과연 100% 이해를 하고 있을까 라는 의문이 들었기 때문이다. 그래서 혼공학습단이 끝날 쯤이나 끝나고 나면 챕터별로 나눠서 재정리를 해볼까 싶다. 그때는 그림도 체계적으로 그리던가 캡처를 딴다는 식으로 내가 해당 파트에 어떤 부분을 다시 보고 싶을 때 블로그의 글로만으로도 이해가 될 수 있도록 정리해보고 싶다.
다음 4주차부터는 운영체제를 배우게 되는데 기대가 된다. 미리 1회독은 했지만.. 이해가 안되는 부분이 또 있기에 ㅋㅋ;;
'Book' 카테고리의 다른 글
| [혼공컴운] 혼공학습단11기_5주차+기본미션 (3) | 2024.02.04 |
|---|---|
| [혼공컴운] 혼공학습단11기_4주차+기본미션 (1) | 2024.01.28 |
| [혼공컴운]혼공학습단11기_2주차+기본, 선택미션 (1) | 2024.01.14 |
| [혼공컴운]혼공학습단11기_1주차+기본, 선택미션 (2) | 2024.01.07 |
| 혼공학습단11기_혼공컴운 시작 (0) | 2024.01.07 |



